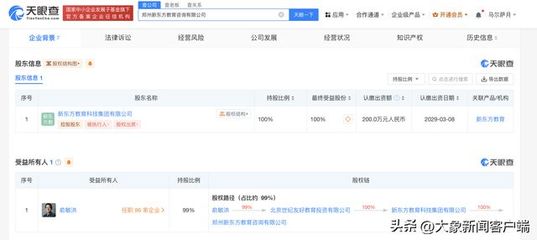
一則關(guān)于新東方在鄭州成立教育咨詢公司的消息,再次引發(fā)了社會(huì)各界對(duì)這家教育巨頭戰(zhàn)略動(dòng)向的關(guān)注。此舉不僅是新東方在“雙減”政策后持續(xù)探索轉(zhuǎn)型路徑的縮影,也預(yù)示著其業(yè)務(wù)重心正從傳統(tǒng)學(xué)科培訓(xùn),向更廣闊的教育咨詢服務(wù)領(lǐng)域拓展。
新成立的鄭州教育咨詢公司,其核心業(yè)務(wù)將聚焦于為學(xué)生與家庭提供專(zhuān)業(yè)的學(xué)業(yè)規(guī)劃、升學(xué)指導(dǎo)、生涯發(fā)展咨詢以及家庭教育支持等服務(wù)。這標(biāo)志著新東方正積極利用其積累多年的教育資源、師資力量與品牌信譽(yù),深入挖掘教育產(chǎn)業(yè)鏈中更具韌性與潛力的價(jià)值環(huán)節(jié)。在當(dāng)前教育政策環(huán)境下,此類(lèi)非學(xué)科類(lèi)、以能力培養(yǎng)和規(guī)劃為導(dǎo)向的服務(wù),正契合了市場(chǎng)對(duì)素質(zhì)教育與個(gè)性化教育日益增長(zhǎng)的需求。
選擇鄭州作為布局點(diǎn),則體現(xiàn)了新東方對(duì)區(qū)域市場(chǎng)的精準(zhǔn)考量。鄭州作為國(guó)家中心城市和中原城市群核心,擁有龐大的學(xué)生基數(shù)、旺盛的教育需求以及輻射周邊的區(qū)位優(yōu)勢(shì)。在此設(shè)立咨詢公司,有助于新東方深耕中原市場(chǎng),更貼近本地家庭的實(shí)際需求,提供更具針對(duì)性的服務(wù),同時(shí)也為其全國(guó)性的網(wǎng)絡(luò)化布局增添了重要一環(huán)。
從宏觀視角看,這一舉措是新東方后“雙減”時(shí)代轉(zhuǎn)型戰(zhàn)略的延續(xù)與深化。自轉(zhuǎn)型以來(lái),新東方已涉足直播帶貨、研學(xué)營(yíng)地、素質(zhì)教育產(chǎn)品等多個(gè)領(lǐng)域。成立教育咨詢公司,可以看作是其在堅(jiān)守教育主航道的向產(chǎn)業(yè)鏈上下游延伸,構(gòu)建更完整、更多元服務(wù)生態(tài)的關(guān)鍵一步。咨詢業(yè)務(wù)能夠有效鏈接其原有的師資、課程資源與終端用戶,形成服務(wù)閉環(huán),增強(qiáng)用戶粘性。
機(jī)遇與挑戰(zhàn)并存。教育咨詢市場(chǎng)本身競(jìng)爭(zhēng)激烈,且對(duì)服務(wù)的專(zhuān)業(yè)性、個(gè)性化程度要求極高。新東方需要將其品牌影響力有效轉(zhuǎn)化為咨詢業(yè)務(wù)的口碑,并構(gòu)建標(biāo)準(zhǔn)化的服務(wù)流程與高質(zhì)量的咨詢師團(tuán)隊(duì)。如何清晰界定咨詢服務(wù)的邊界,避免與已受限的學(xué)科培訓(xùn)產(chǎn)生混淆,確保合規(guī)經(jīng)營(yíng),也是其必須面對(duì)的重要課題。
總而言之,新東方在鄭州成立教育咨詢公司,是一次順應(yīng)時(shí)勢(shì)的戰(zhàn)略選擇。它不僅是企業(yè)自身尋求新增長(zhǎng)點(diǎn)的探索,也反映了中國(guó)教育培訓(xùn)行業(yè)從規(guī)模擴(kuò)張轉(zhuǎn)向質(zhì)量提升、從應(yīng)試導(dǎo)向轉(zhuǎn)向全面發(fā)展的大趨勢(shì)。其后續(xù)發(fā)展,能否真正滿足家庭對(duì)科學(xué)教育規(guī)劃的需求,并為行業(yè)轉(zhuǎn)型提供可行范本,值得我們持續(xù)關(guān)注。